
تقریباً تمام نوآوریهای فناوری در چند سال اخیر به یک هدف متمرکز شدهاند: هوش مصنوعی مولد. اکثر این سیستمهای ادعایی انقلابی روی سرورهای بزرگ و پرهزینه در یک مرکز داده اجرا میشوند، اما بههمزمان سازندگان تراشهها دربارهٔ قدرت واحدهای پردازش عصبی (NPU) که به دستگاههای مصرفکننده افزودهاند، به خود میبالند. هر چند ماه یکبار همان گفتار تکرار میشود: این NPU جدید ۳۰ تا ۴۰ درصد سریعتر از نسخهٔ قبلی است. این ادعا میکند که میتواند کاری مهم برای شما انجام دهد، اما هیچکس واقعاً توضیح نمیدهد که این کار دقیقاً چیست.
متخصصان آیندهای را پیشبینی میکنند که ابزارهای هوش مصنوعی امن و شخصی با هوش محلی در دستگاه داشته باشند، اما آیا این تصور با واقعیت رونق هوش مصنوعی همخوانی دارد؟ هوش مصنوعی در «لبه» (edge) بهنظر عالی میآید، اما تقریباً تمام ابزارهای مهم هوش مصنوعی در ابر اجرا میشوند. پس آن تراشه در گوشی شما چه کاری انجام میدهد؟
واحد پردازش عصبی (NPU) چیست؟
شرکتهایی که محصول جدیدی را معرفی میکنند، اغلب در توصیفات رسا و بیانهای بازاریابی نامشخص غرق میشوند؛ بهطوری که جزئیات فنی را بهخوبی توضیح نمیدهند. برای اکثر خریداران تلفن واضح نیست که چرا به سختافزاری برای اجرای بارهای کاری هوش مصنوعی نیاز دارند و فواید ادعایی معمولاً نظری باقی میمانند.
بسیاری از پردازندههای پرچمدار مصرفکننده امروز، سیستمهای روی تراشه (SoC) هستند؛ چرا که عناصر محاسبهای متعددی نظیر هستههای CPU، GPU و کنترلکنندههای تصویری را بر روی یک قطعه سیلیکونی ترکیب میکنند. این ویژگی نه تنها برای قطعات موبایلی مانند Snapdragon شرکت Qualcomm یا Tensor گوگل صادق است، بلکه برای مؤلفههای رایانهای مانند Intel Core Ultra نیز صدق میکند.
واحد پردازش عصبی (NPU) بهعنوان افزونهای نوین به تراشهها اضافه شده است، اما ناگهان ظاهر نشده؛ یک سیر تکاملی که ما را به این نقطه رسانده است. NPUها در کار خود توانمندند زیرا بر پردازش موازی تأکید دارند؛ ویژگیای که در سایر مؤلفههای SoC نیز حائز اهمیت است.
Qualcomm در اعلامهای محصول جدید خود زمان قابلتوجهی را به معرفی NPUهای Hexagon اختصاص میدهد. ناظران میتوانند به یاد داشته باشند که این نامگذاری قبلاً برای پردازشگرهای سیگنال دیجیتال (DSP) این شرکت استفاده میشده و دلیل منطقی برای این تکرار وجود دارد.
«سفر ما به سمت پردازش هوش مصنوعی احتمالاً حدود ۱۵ تا ۲۰ سال پیش آغاز شد و اولین نقطهٔ عطفمان در پردازش سیگنال بود»، ویندس سوکومار، رئیس محصولات هوش مصنوعی Qualcomm، گفت. DSPها معماری مشابهی نسبت به NPUها دارند، اما بهمراتب سادهترند و تمرکزشان بر پردازش صوت (مثلاً شناسایی گفتار) و سیگنالهای مودم است.

با پیشرفت مجموعهٔ تکنولوژیهایی که بهعنوان «هوش مصنوعی» میشناسیم، مهندسان شروع به استفاده از DSPها برای انواع بیشتری از پردازشهای موازی کردند، مثل شبکه حافظه طولانی‑کوتاهمدت (LSTM). سوکومار توضیح داد که با شیفت صنعتی به سمت شبکههای عصبی کانولوشنی (CNN) — فناوری پایهای برنامههایی مثل دید کامپیوتری — DSPها تمرکز بیشتری بر توابع ماتریسی یافتند؛ توابعی که برای پردازش هوش مصنوعی مولد نیز ضروریاند.
اگرچه یک سیر معماری در این زمینه وجود دارد، گفتن اینکه NPUها تنها DSPهای پیشرفتهاند دقیقاً صحیح نیست. «اگر در مفهوم کلی به DSPها بپردازیم، بله، یک NPU نیز نوعی پردازشگر سیگنال دیجیتال است»، مارک اودانی، معاون رئیسجمهوری معاونِ میدیاتک، گفت. «اما این فناوری مسیر طولانیای را طی کرده و برای پردازش موازی، نحوهٔ کار توابع تبدیل (transformers) و نگهداری تعداد عظیمی از پارامترها بهطور قابلتوجهی بهینهسازی شده است.»
علیرغم حضور چشمگیر NPUها در تراشههای نوین، آنها برای اجرای بارهای کاری هوش مصنوعی بر روی «لبه» (edge) — اصطلاحی که پردازش محلی هوش مصنوعی را از سیستمهای مبتنی بر ابر متمایز میکند — الزامی ندارند. پردازندههای مرکزی (CPU) نسبت به NPUها سرعت کمتری دارند، اما میتوانند بارهای کاری سبک را با مصرف انرژی کمتر بر عهده بگیرند. در مقابل، واحدهای پردازش گرافیکی (GPU) معمولاً میتوانند مقدار بیشتری داده را پردازش کنند، ولی برای این کار انرژی بیشتری مصرف میکنند. گاهی اوقات ممکن است این ترجیح داده شود؛ بهعنوان مثال، اجرای بارهای کاری هوش مصنوعی همزمان با یک بازی میتواند به نفع GPU باشد، طبق گفتهٔ سوکومار از Qualcomm.
زندگی در لبه (Edge) دشوار است
متأسفانه NPUهای بسیاری از دستگاهها در حالت بیکار میمانند (و نه فقط در زمان بازی). ترکیب ابزارهای هوش مصنوعی محلی و ابری به نفع دوم است، زیرا این محیط طبیعی برای مدلهای بزرگ زبانی (LLM) میباشد. مدلهای هوش مصنوعی بر روی سرورهای قدرتمند آموزش میبینند و تنظیم میشوند و در همانجا بهترین عملکرد را دارند.
هوش مصنوعی مبتنی بر سرور، مانند نسخههای کامل Gemini و ChatGPT، محدودیت منابعی مشابه مدلی که بر روی NPU گوشی شما اجرا میشود، ندارد. بهعنوان مثال، آخرین نسخهٔ مدل Gemini Nano روی دستگاه گوگل دارای پنجرهٔ متنی ۳۲ هزار توکن است؛ که این بیش از دو برابر بهبود نسبت به نسخهٔ پیشین است. اما مدلهای Gemini مبتنی بر ابر، پنجرهٔ متنی تا یک میلیون توکن دارند و میتوانند حجم بسیار بزرگتری از دادهها را پردازش کنند.
سختافزارهای هوش مصنوعی مبتنی بر ابر و لبه بهتدریج پیشرفت خواهند کرد، اما تعادل ممکن است به نفع NPU تغییر نکند. «ابر همیشه منابع محاسباتی بیشتری نسبت به یک دستگاه موبایل خواهد داشت»، شناز زاک، مدیر محصول ارشد تیم پیکسل گوگل، اعلام کرد.
«اگر به دنبال دقیقترین مدلها یا مدلهای پرقدرتترین هستید، این کار باید در ابر انجام شود»، اودانی گفت. «اما آنچه میبینیم این است که در بسیاری از موارد استفاده که صرفاً خلاصهسازی متن یا گفتگو با دستیار صوتی است، این کارها میتوانند در چارچوب سه میلیارد پارامتر جای بگیرند.»
مسئلهٔ اعتماد
اگر ابر سریعتر و آسانتر است، چرا زحمت بهینهسازی برای لبه و مصرف انرژی بیشتر توسط NPU را میپذیریم؟ تکیه بر ابر مستلزم پذیرش سطحی از وابستگی و اعتماد به افراد مدیریتکنندهٔ مراکز داده هوش مصنوعی است که همیشه ممکن است مناسب نباشد.
«ما همواره با حریم خصوصی کاربر شروع میکنیم»، سوکومار از Qualcomm گفت. او توضیح داد که بهترین استنتاج، بهصورت عمومی نیست؛ بلکه بر اساس علاقهمندیهای کاربر و وضعیت زندگی او شخصیسازی میشود. تنظیم دقیق مدلها برای ارائه چنین تجربهای نیازمند دادههای شخصی است و ایمنتر است که این دادهها بهصورت محلی ذخیره و پردازش شوند.
حتی وقتی شرکتها دربارهٔ حریم خصوصی در خدمات ابری خود حرفهای درستی میزنند، اینها هیچگونه تضمینی نیستند. فضای دوستانه و مفید روباتهای گفتوگو عمومی، مردم را تشویق میکند تا اطلاعات شخصی زیادی را فاش کنند؛ و اگر این دستیار در ابر اجرا شود، دادههای شما نیز همانجا ذخیره میشود. مبارزهٔ حقنشر OpenAI با The New York Times میتواند منجر به تحویل میلیونها گفتوگوی خصوصی به انتشارات شود. رشد انفجاری و چارچوب نظارتی نامشخص هوش مصنوعی مولد، دانستن آیندهٔ دادههای شما را دشوار میسازد.
تسلط ابر
بهنظر میرسد همه توافق داشته باشند که برای ارائهٔ ویژگیهای واقعاً مفید هوش مصنوعی (در صورتی که چنین ویژگیهایی وجود داشته باشند) نیاز به رویکرد ترکیبی است؛ یعنی در زمان نیاز، دادهها به سرویسهای قویتر ابری ارسال میشوند — گوگل، اپل و تمام تولیدکنندگان تلفن همراه این کار را انجام میدهند. اما تعقیب تجربهای یکپارچه میتواند آنچه در پشت پردهٔ دادههای شما اتفاق میافتد را مخفی کند. بیشتر اوقات، ویژگیهای هوش مصنوعی در تلفن شما بهصورت امن و محلی اجرا نمیشوند، حتی اگر دستگاه دارای سختافزاری برای این منظور باشد.
بهعنوان مثال، به تلفن جدید OnePlus 15 نگاهی بیندازید. این گوشی دارای Snapdragon 8 Elite Gen 5 جدید شرکت Qualcomm است که NPU آن ۳۷ درصد سریعتر از نسل قبلی است — هرچند این سرعت چهقدر ارزشمند است. حتی با این توانایی هوش مصنوعی محلی، OnePlus بهطور قابلتوجهی به ابر برای تجزیه و تحلیل دادههای شخصی شما وابسته است. ویژگیهایی مانند AI Writer و AI Recorder برای پردازش به سرورهای شرکت متصل میشوند؛ سیستمی که OnePlus تضمین میکند کاملاً امن و حریم خصوصی حفظ میشود.
بهطور مشابه، Motorola در طول تابستان خط جدیدی از تلفنهای تاشو Razr را رونمایی کرد که پر از ویژگیهای هوش مصنوعی از چندین ارائهدهنده هستند. این گوشیها میتوانند اعلانهای شما را با هوش مصنوعی خلاصه کنند، اما ممکن است تعجب کنید که چه مقدار این کار در ابر انجام میشود مگر اینکه شرایط و ضوابط را بخوانید. اگر Razr Ultra را خریداری کنید، خلاصهسازی بر روی گوشی شما انجام میشود؛ اما مدلهای ارزانتر با RAM و توان NPU کمتر، برای پردازش اعلانها از خدمات ابری استفاده میکنند. بار دیگر Motorola میگوید این سیستم ایمن است، اما گزینهای امنتر میتوانست مدل را برای این گوشیهای کمقیمت بهصورت بهینهسازی مجدد کند.
حتی زمانی که یک تولیدکننده (OEM) تمرکز خود را بر استفاده از سختافزار NPU بگذارد، نتایج ممکن است کمرنگ بماند. به Daily Hub گوگل و Now Brief سامسونگ نگاهی بیندازید؛ این ویژگیها قرار است تمام دادههای گوشی شما را تجزیه و تحلیل کنند و پیشنهادات و اقدامات مفیدی تولید نمایند، اما به ندرت چیزی جز نمایش رویدادهای تقویم انجام میدهند. در واقع، گوگل به طور موقت Daily Hub را از دستگاههای Pixel حذف کرده است چون این ویژگی کمکاری کرد؛ در حالی که گوگل پیشگام هوش مصنوعی محلی با Gemini Nano است. در ماههای اخیر، گوگل برخی بخشهای تجربه هوش مصنوعی موبایلی خود را از پردازش محلی به پردازش ابری منتقل کرده است.
شاید همانچه میتوانید بگیرید
علاقهٔ فراوانی به هوش مصنوعی محلی وجود دارد، اما تاکنون این علاقه به انقلاب هوش مصنوعی در جیب شما منجر نشده است. بیشتر پیشرفتهای هوش مصنوعی که تا کنون مشاهده کردهایم به مقیاس روزافزونی که ابرها دارند و به مدلهای عمومی که در آن اجرا میشوند، وابسته است. کارشناسان صنعت میگویند کارهای گستردهای در پشت صحنه برای کوچککردن مدلهای هوش مصنوعی بهگونهای که بر روی گوشیها و لپتاپها کار کنند، انجام میشود، اما برای اثرگذاری این کار زمان میبرد.
در این میان، پردازش هوش مصنوعی محلی بهصورت محدود موجود است. گوگل همچنان از NPU Tensor برای مدیریت دادههای حساس در ویژگیهایی مانند Magic Cue استفاده میکند و سامسونگ واقعا از چیپستهای متمرکز بر هوش مصنوعی Qualcomm بهنحو حداکثری بهره میبرد. اگرچه Now Brief کارایی مشکوکی دارد، سامسونگ آگاه است که وابستگی به ابر چگونه میتواند بر کاربران تأثیر بگذارد؛ بنابراین یک کلید تنظیم در تنظیمات سیستم ارائه میدهد که پردازش هوش مصنوعی را فقط بر روی دستگاه محدود میکند. این کار تعداد ویژگیهای هوش مصنوعی موجود را محدود میکند و برخی دیگر عملکرد کمتری دارند، اما اطمینان میدهد که هیچیک از دادههای شخصی شما به اشتراک گذاشته نمیشود. هیچ برند دیگری این گزینه را برای گوشیهای هوشمند فراهم نمیکند.
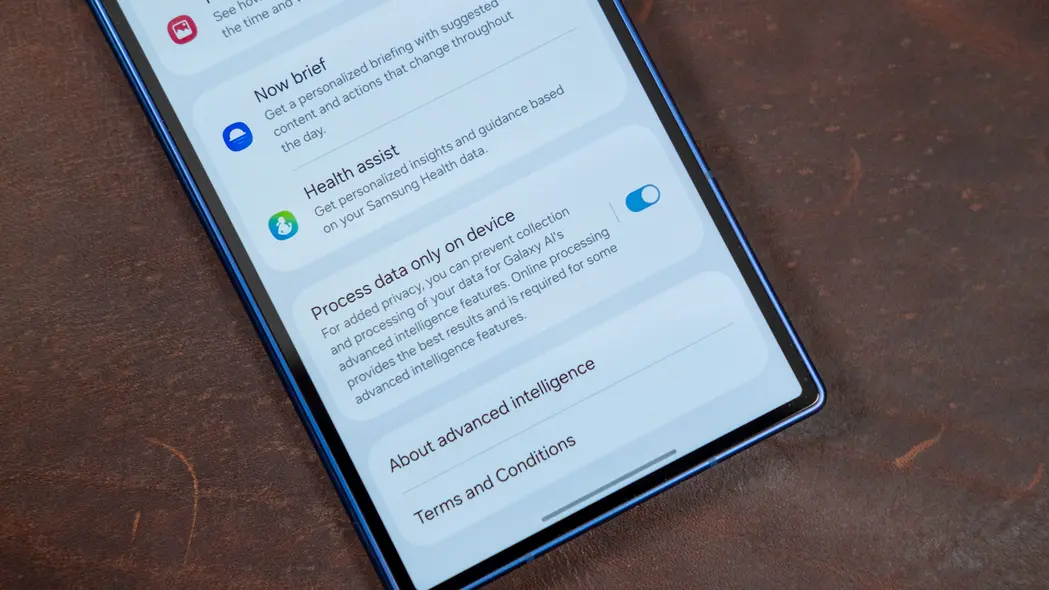
سخنگوی سامسونگ، الیز سِمباخ، گفت که تلاشهای هوش مصنوعی شرکت بر پایه ارتقاء تجربه کاربران در حالی است که کنترل را در اختیار کاربر میگذارد. «دکمهٔ تعویض پردازش محلی در One UI این رویکرد را نمایان میکند؛ با آن کاربران میتوانند وظایف هوش مصنوعی را بهصورت محلی پردازش کنند که منجر به عملکرد سریعتر، حریم خصوصی بیشتر و قابلیت اطمینان حتی در نبود اتصال شبکه میشود»، سِمباخ افزود.
علاقه به هوش مصنوعی لبه (edge) میتواند حتی در صورتی که از آن استفاده نکنید، مفید باشد. برنامهریزی برای این آیندهٔ پر از هوش مصنوعی میتواند سازندگان دستگاهها را ترغیب کند تا در سختافزار بهتر سرمایهگذاری کنند — مثلاً حافظهٔ بیشتری برای اجرای تمام آن مدلهای نظری هوش مصنوعی.
«ما قطعاً توصیه میکنیم که شرکایمان ظرفیت RAM خود را افزایش دهند»، سوکومار افزود. در واقع، گوگل، سامسونگ و دیگران بهطور عمده حجم حافظهٔ خود را برای پشتیبانی از هوش مصنوعی محلی افزایش دادهاند. حتی اگر ابر برتری داشته باشد، ما همچنان به RAM اضافی نیاز داریم.