توسط پل آرنولد، Phys.org
در المپیاد بینالمللی ریاضیات (IMO) سال ۲۰۲۴، یک شرکتکننده آنقدر موفق شد که شایسته دریافت جایزه نقره میشد؛ اما یک نکته مانع این شد: این شرکتکننده یک سامانهٔ هوش مصنوعی بود. این نخستین بار بود که هوش مصنوعی عملکردی در سطح مدال در تاریخ این مسابقه بهدست آورد. در مقالهای که در ژورنال Nature منتشر شد، پژوهشگران فناوری پشت این دستاورد شگفتانگیز را شرح میدهند.
این هوش مصنوعی AlphaProof نام دارد، برنامهای پیشرفته که توسط Google DeepMind توسعه یافته و به حل مسائل پیچیدهٔ ریاضی میپردازد. دستاورد در IMO بهتنهایی چشمگیر بود، اما چیزی که AlphaProof را متمایز میکند، تواناییاش در شناسایی و اصلاح خطاهاست. اگرچه مدلهای بزرگ زبانی (LLMs) میتوانند مسائل ریاضی را حل کنند، اما اغلب قادر به تضمین صحت راهحلهایشان نیستند. ممکن است نقصهای پنهانی در استدلال آنها وجود داشته باشد.
AlphaProof متفاوت است زیرا پاسخهایش همیشه ۱۰۰٪ درست هستند. دلیل این امر استفاده از محیط نرمافزاری ویژهای به نام Lean است (که اولیه توسط Microsoft Research توسعه یافته) که شبیه یک معلم سختگیر عمل کرده و هر گام منطقی را تأیید میکند. این بدان معناست که خود کامپیوتر پاسخها را بررسی میکند و بنابراین نتایج آن قابل اعتماد هستند.
روند آموزش سه مرحلهای
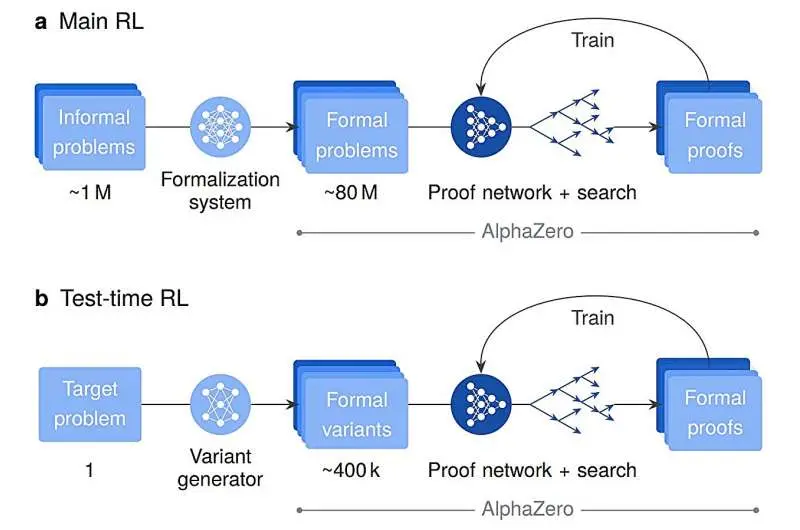
آموزش این سیستم قدرتمند برای استدلال در سطح برتر شامل سه مرحلهٔ متفاوت آموزشی بود. ابتدا، پژوهشگران AlphaProof را با حدود ۳۰۰ میلیارد توکن از کد عمومی و متون ریاضی آشنا کردند تا درک گستردهای از مفاهیمی همچون منطق، زبان ریاضی و ساختار برنامهنویسی به دست آورد. سپس، ۳۰۰٬۰۰۰ اثبات ریاضی نوشته شده توسط متخصصان که از پیش در محیط Lean موجود بودند، به آن داده شد.
مرحلهٔ نهایی جایی بود که سیستم یاد گرفت بهتنهایی مسائل را حل کند. برای آن یک تکلیف خانگی عظیم شامل ۸۰ میلیون مسئلهٔ ریاضی رسمی تعیین شد. با استفاده از یادگیری تقویتی (RL) که بر پایه آزمون و خطا است، AlphaProof برای هر اثبات موفق پاداش دریافت کرد. با پردازش مقیاسی چنین وسیعی از مسائل ریاضی، سیستم بهطور خودآموز استراتژیهای استدلالی جدید و پیچیدهای را توسعه داد که فراتر از کپیکردن مثالهای انسانی بود.
برای سختترین مسائل، AlphaProof از تکنیکی که پژوهشگران آن را «یادگیری تقویتی زمانآزمون» (Test‑Time RL یا TTRL) نامگذاری کردهاند، استفاده کرد؛ این روش نسخههای سادهسازی شدهٔ میلیونها برابر از مسئلهٔ هدف را ایجاد و حل میکند تا سرانجام به یک راهحل دست یابد.
«کار ما نشان میدهد که یادگیری در مقیاس بزرگ از تجربهٔ واقعی، عوامل را به استراتژیهای استدلالی پیچیدهٔ ریاضی تبدیل میکند و راه را برای یک ابزار هوش مصنوعی قابل اعتماد در حل مسائل ریاضی پیچیده هموار میسازد»، پژوهشگران در مقالهٔ خود نوشتند.
علاوه بر حل مسائلی که بهنظر غیرقابل حل میرسند، AlphaProof میتواند توسط ریاضیدانان برای تصحیح کارهایشان و کمک به توسعه نظریههای جدید نیز به کار گرفته شود.
اطلاعات بیشتر: Thomas Hubert et al, Olympiad‑level formal mathematical reasoning with reinforcement learning, Nature (2025). DOI: 10.1038/s41586-025-09833-y
اطلاعات نشریه: Nature
استناد: نابغهٔ ریاضی هوش مصنوعی نتایج ۱۰۰٪ دقیق را ارائه میدهد (2025، ۱۴ نوامبر) بازیابیشده ۱۷ نوامبر 2025 از https://phys.org/news/2025-11-ai-math-genius-accurate-results.html