
توسط Tanu Jain، Alex Kube، Timotej Kapus
- چارچوبهای امن‑پیشفرض متا، توابع احتمالی ناامن سیستمعامل و سرویسهای شخص ثالث را میپوشانند تا امنیت بهصورت پیشفرض باشد و در عین حال سرعت و سهولت توسعهدهندگان حفظ شود.
- این چارچوبها بهگونهای طراحی شدهاند که APIهای موجود را بهدقت شبیهسازی کنند، بر روی رابطهای عمومی و پایدار تکیه داشته باشند و با کاهش اصطکاک و پیچیدگی، پذیرش توسعهدهندگان را به حداکثر برسانند.
- هوش مصنوعی تولیدی و خودکارسازی پذیرش چارچوبهای امن را در مقیاس وسیع تسریع میکنند و امکان اجرای مستمر امنیت و مهاجرت کارآمد در سراسر کدبیس وسیع متا را فراهم میسازند.
گاهی توابعی که در سیستمعاملها یا توسط طرفهای ثالث ارائه میشوند، خطر سوءاستفاده دارند که میتواند امنیت را به خطر اندازد. برای کاهش این خطر، ما این توابع را با استفاده از چارچوبهای امن‑پیشفرض خود میپوشانیم یا جایگزین میکنیم. این چارچوبها نقش مهمی در کمک به مهندسان امنیت و نرمافزار ما برای حفظ و ارتقاء امنیت کدبیسها دارند، در حالی که سرعت توسعهدهندگان را نیز حفظ میکنند.
اما پیادهسازی این چارچوبها همراه با چالشهای عملی است، مانند تضادهای طراحی. ساخت یک چارچوب امن بر پایه APIهای اندروید، برای مثال، نیازمند تعادل دقیقی بین امنیت، کارایی و قابلیت نگهداری است.
با ظهور ابزارهای مبتنی بر هوش مصنوعی و خودکارسازی، میتوانیم پذیرش این چارچوبها را در کدبیس بزرگ متا گسترش دهیم. هوش مصنوعی میتواند در شناسایی الگوهای ناامن، پیشنهاد یا اعمال خودکار جایگزینهای چارچوب امن، و نظارت مستمر بر رعایت قوانین کمک کند. این نه تنها مهاجرت را تسریع میکند، بلکه اجرای مستمر امنیت در مقیاس وسیع را نیز تضمین میسازد.
این استراتژیها به تیمهای توسعهمان این امکان را میدهند تا نرمافزارهای امن را بهصورت کارآمد ارائه دهند، دادهها و اعتماد کاربران را محافظت کنند، در حالی که بهرهوری بالای توسعهدهندگان را در سراسر اکوسیستم وسیع متا حفظ مینمایند.
چگونه چارچوبهای امن‑پیشفرض را در متا طراحی میکنیم
طراحی چارچوبهای امن‑پیشفرض برای استفاده توسط تعداد زیادی از توسعهدهندگانی که ویژگیهای متفاوتی را در چندین برنامه منتشر میکنند، یک چالش جالب است. عوامل متقابل متعددی مانند قابلیت کشف، کارایی، قابلیت نگهداری، عملکرد و مزایای امنیتی وجود دارد.
در عمل، توسعهدهندگان تنها زمان محدودی برای برنامهنویسی در هر روز دارند. هدف چارچوبهای ما بهبود امنیت محصول است در حالی که بهطور عمده نامرئی و بدون اصطکاک باشند تا از کاهش سرعت توسعهدهندگان بهطور غیرضروری جلوگیری شود. این بدان معناست که باید تعادل مناسب بین تمام موارد متقابل ذکر شده در بالا برقرار کنیم. اگر تعادلی نادرست برقرار شود، برخی توسعهدهندگان ممکن است از استفاده از چارچوبهای ما خودداری کنند که میتواند توانایی ما در پیشگیری از آسیبپذیریهای امنیتی را کاهش دهد.
برای مثال، اگر چارچوبی را طراحی کنیم که امنیت محصول را در یک حوزه بهبود میدهد ولی سه مفهوم جدید معرفی میکند و از توسعهدهندگان میخواهد برای هر نقطه فراخوانی پنج اطلاعات اضافی فراهم کنند، برخی توسعهدهندگان اپلیکیشن ممکن است سعی کنند راهی برای دور زدن استفاده از آن پیدا کنند. برعکس، اگر همان چارچوبها را بهصورت کاملاً ساده ارائه دهیم، اما مقدار قابل ملاحظهای از پردازنده (CPU) و حافظه (RAM) مصرف کنند، برخی توسعهدهندگان ممکن است دوباره به دنبال راههای دور زدن استفاده از آن باشند، هرچند به دلایل متفاوت.
این مثالها ممکن است کمی واضح به نظر برسند، اما از تجربیات واقعی در طول بیش از ۱۰ سال توسعه حدود ۱۵ چارچوب امن‑پیشفرض هدفدار برای اندروید و iOS استخراج شدهاند. در طول این مدت، ما برخی از بهترین شیوهها را برای طراحی و پیادهسازی این چارچوبهای جدید بهدست آوردهایم.
بهقدر ممکن، یک چارچوب مؤثر باید اصول زیر را تجسم کند:
- API چارچوب امن باید شبیه API موجود باشد. این کار بار شناختی کاربران چارچوب را کاهش میدهد، توسعهدهندگان چارچوب امنیتی را مجبور میکند تا پیچیدگی تغییرات را به حداقل برسانند و تبدیل خودکار کد از استفاده از API ناامن به API امن را آسانتر میکند.
- چارچوب باید خود بر پایه APIهای عمومی و پایدار ساخته شود. APIهای تولیدکنندگان سیستمعامل و طرفهای ثالث بهطور مداوم تغییر میکنند، بهخصوص APIهای غیرعمومی. حتی اگر دسترسی به این APIها در برخی موارد از نظر فنی مجاز باشد، ساختن بر پایه APIهای خصوصی منجر به حالات مانند آزمونهای اضطراری مداوم (بهترین حالت) و سرمایهگذاری بینتیجه در چارچوبهایی میشود که بهسادگی با نسخههای جدیدتر سیستمعاملها و کتابخانهها کار نمیکند (بدترین حالت).
- چارچوب باید بیشترین تعداد کاربران برنامه را پوشش دهد، نه صرفاً موارد استفاده امنیتی. نباید یک چارچوب امنیتی باشد که تمام مسائل امنیتی را پوشش دهد، و هر مسئله امنیتی بهصورت کلی کافی نیست تا چارچوب ویژهای داشته باشد. با این حال، هر چارچوب امنیتی باید برای تمام برنامهها و نسخههای سیستمعامل یک پلتفرم خاص قابل استفاده باشد. کتابخانههای کوچک سریعتر ساخته و مستقر میشوند و نگهداری و توضیح آنها برای توسعهدهندگان برنامهها آسانتر است.
حال که نگاهی به فلسفه طراحی چارچوبهای ما انداختیم، بیایید به یکی از چارچوبهای امنیتی اندروید که بهطور گسترده استفاده میشود، SecureLinkLauncher، نگاهی بیاندازیم.
SecureLinkLauncher: جلوگیری از ربودن Intent در اندروید
SecureLinkLauncher (SLL) یکی از چارچوبهای امن پرکاربرد ما است. SLL برای جلوگیری از افشای دادههای حساس از طریق سیستم Intentهای اندروید طراحی شدهاست. این چارچوب نمونهای از رویکرد ما به چارچوبهای امن‑پیشفرض است که با پوشاندن روشهای بومی اجرای Intent در اندروید، همراه با تأیید دامنه و بررسیهای امنیتی، از آسیبپذیریهای رایج مثل ربودن Intent جلوگیری میکند، بدون اینکه سرعت یا آشنایی توسعهدهندگان قربانی شود.
این سیستم شامل فرستندههای Intent و گیرندههای Intent است. SLL هدفش فرستندههای Intent است.
SLL یک API معنایی فراهم میکند که بهدقت API آشنای Android Context را برای راهاندازی Intentها بازتاب میدهد، شامل متدهایی مانند startActivity() و startActivityForResult(). بهجای فراخوانی مستقیم API اندروید که ممکن است ناامن باشد، مانند context.startActivity(intent);، توسعهدهندگان از SecureLinkLauncher با الگوی فراخوانی مشابه استفاده میکنند؛ به عنوان مثال SecureLinkLauncher.launchInternalActivity(intent, context). درون چارچوب، SecureLinkLauncher به API پایدار Android startActivity() واگذار میشود، بهطوری که همه راهاندازیهای Intent بهصورت امن تأیید و توسط چارچوب محافظت میشوند.
public void launchInternalActivity(Intent intent, Context context) {
// Verify that the target activity is internal (same package)
if (!isInternalActivity(intent, context)) {
throw new SecurityException("Target activity is not internal");
}
// Delegate to Android's startActivity to launch the intent
context.startActivity(intent);
}
بهطور مشابه، بهجای فراخوانی مستقیم context.startActivityForResult(intent, code);، توسعهدهندگان از SecureLinkLauncher.launchInternalActivityForResult(intent, code, context) استفاده میکنند. SecureLinkLauncher (SLL) متدهای startActivity() اندروید و متدهای مرتبط را میپوشاند، با تأیید دامنه پیش از واگذار به API بومی اندروید. این رویکرد امنیت را بهصورت پیشفرض فراهم میکند در حالی که مفاهیم آشنای راهاندازی Intentهای اندروید را حفظ میکند.
یکی از رایجترین روشهای نشت دادهها از طریق Intentها، بهدلیل هدفگذاری نادرست Intent است. برای مثال، Intent زیر بهصورت خاص به یک بسته هدفگذاری نشده است. این به این معناست که میتواند توسط هر برنامهای که فیلتر Intent مرتبط دارد دریافت شود. در حالی که هدف توسعهدهنده ممکن است این باشد که Intent آنها بر پایه URL به برنامه فیسبوک هدایت شود، واقعیت این است که هر برنامهای، از جمله برنامه مخرب، میتواند فیلتر Intentی اضافه کند که آن URL را پردازش کند و Intent را دریافت نماید.
Intent intent = new Intent(FBLinks.PREFIX + "profile");
intent.setExtra(SECRET_INFO, user_id);
startActivity(intent);
// startActivity can’t ensure who the receiver of the intent would be
در مثال زیر، SLL اطمینان میدهد که Intent به یکی از برنامههای خانواده هدایت میشود، همانطور که دامنه تعیینشده توسط توسعهدهنده برای Intentهای ضمنی مشخص شده است. بدون SLL، این Intentها میتوانند به هر دو برنامه خانواده و غیرخانواده حل شوند، که ممکن است SECRET_INFO را به برنامههای شخص ثالث یا مخرب روی دستگاه کاربر افشا کند. با اعمال این دامنه، SLL میتواند از چنین نشت اطلاعاتی جلوگیری کند.
SecureLinkLauncher.launchFamilyActivity(intent, context);
// launchFamilyActivity would make sure intent goes to the meta family apps
در یک محیط معمولی اندروید، دو دامنه – داخلی و خارجی – ممکن است برای مدیریت Intentها درون یک برنامه و بین برنامههای مختلف کافی به نظر برسند. اما اکوسیستم متا منحصر بهفرد است و شامل برنامههای متعددی مانند فیسبوک، اینستاگرام، مسنجر، واتساپ و انواع آن (مانند واتساپ کسبوکار) میشود. پیچیدگی ارتباط بین این برنامهها نیازمند کنترل دقیقتری بر دامنه Intent است. برای رفع این نیاز، SLL رویکردی دقیقتر برای دامنه Intent فراهم میکند، دامنههایی که برای استفادههای خاص طراحی شدهاند:
- دامنه خانوادگی: امکان ارتباط امن بین برنامههای متعلق به متا را فراهم میکند و اطمینان میدهد که Intentها تنها از یک برنامه متا به برنامه دیگر متا ارسال میشوند.
- دامنه کلید یکسان: ارسال Intentها را به برنامههای متا که با همان کلید امضا شدهاند محدود میکند (همه برنامههای متا با یک کلید امضا نشدهاند)، و لایهای اضافی از امنیت و اعتماد فراهم میآورد.
- دامنه داخلی: ارسال Intentها را درون خود برنامه محدود میکند.
- دامنه شخص ثالث: امکان ارسال Intentها به برنامههای شخص ثالث را میدهد، در حالی که از پردازش آنها توسط برنامههای خود متا جلوگیری میکند.
با بهرهگیری از این دامنهها، توسعهدهندگان میتوانند اطمینان حاصل کنند که دادههای حساس بهصورت امن و آگاهانه در داخل اکوسیستم متا به اشتراک گذاشته میشود، در حالی که در مقابل دسترسی ناخواسته یا مخرب محافظت میشود. قابلیتهای دقیق دامنهگذاری Intentهای SLL که بر پایه اصول چارچوبهای امن‑پیشفرض بیانشده در بالا ساخته شدهاند، به توسعهدهندگان این امکان را میدهند تا برنامههای قویتر و امنتری بسازند که نیازهای منحصر بهفرد اکوسیستم پیچیده متا را برآورده سازند.
بهکارگیری هوش مصنوعی تولیدی برای استقرار چارچوبهای امن‑پیشفرض در مقیاس بزرگ
پذیرش این چارچوبها در یک کدبیس بزرگ کار سادهای نیست. پیچیدگی اصلی انتخاب دامنه صحیح است، زیرا این انتخاب به اطلاعاتی وابسته است که بهصورت واضح در نقاط فراخوانی موجود در دسترس نیست. اگرچه میتوان تصور کرد که تحلیلی قطعی سعی کند دامنه را بر پایهٔ جریان دادهها استنتاج کند، این کار یک پروژهٔ بزرگ خواهد بود. علاوه بر این، احتمالاً توازن بین دقت و مقیاسپذیری وجود دارد.
در عوض، ما استفاده از هوش مصنوعی تولیدی را برای این مورد بررسی کردیم. هوش مصنوعی میتواند کدهای اطراف را بخواند و سعی کند دامنه را بر پایهٔ نام متغیرها و توضیحاتی که در اطراف نقطه فراخوانی قرار دارند استنتاج کند. اگرچه این روش همیشه کامل نیست، نیازی به کامل بودن ندارد؛ کافی است حدسهای کافی خوبی ارائه دهد تا مالکان کد بتوانند با یک کلیک اصلاحات پیشنهادی را بپذیرند.
اگر اصلاحات در اکثر موارد صحیح باشند، این یک صرفهجویی بزرگ در زمان است که پذیرش مؤثر چارچوب را امکانپذیر میسازد. این کار مکمل تحقیق اخیر ما درباره AutoPatchBench است، یک معیار طراحیشده برای ارزیابی تولیدکنندگان پچهای هوشمصنوعی که از مدلهای زبانی بزرگ (LLMها) برای پیشنهاد و اعمال خودکار پچهای امنیتی استفاده میکنند. چارچوبهای امن‑پیشفرض نمونهای عالی از انواع تغییرات کدی هستند که یک سیستم خودکار پچ میتواند برای بهبود امنیت یک کدبیس اعمال کند.
ما چارچوبی ساختهایم که از Llama بهعنوان فناوری اصلی استفاده میکند؛ این چارچوب مکانهای کدبیس که میخواهیم مهاجرت کنیم دریافت میکند و پچهایی را برای پذیرش توسط مالکان کد پیشنهاد میدهد:
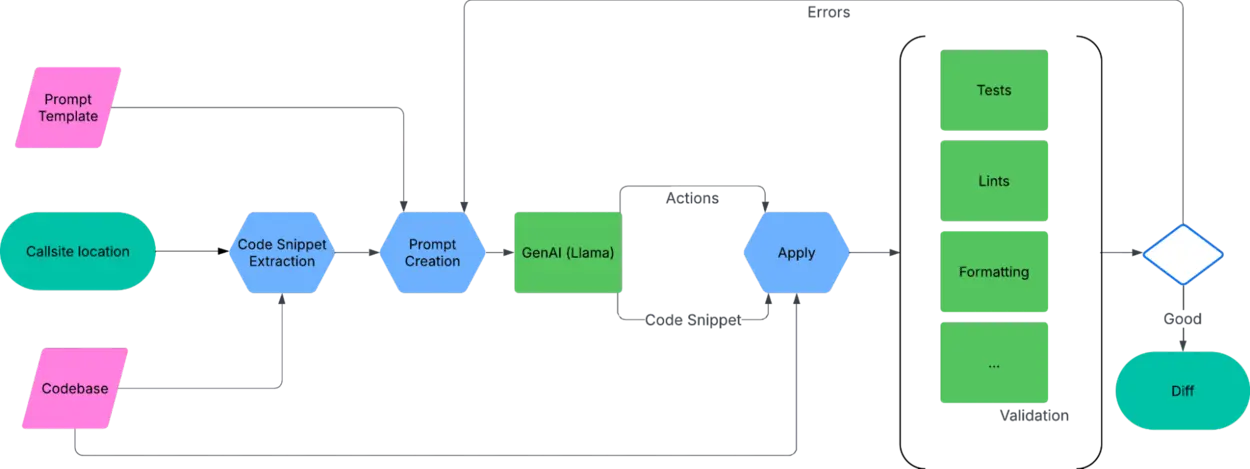
ایجاد Prompt
گردش کار هوش مصنوعی با نقطه