گزارشها حاکی از آن است که «آزمون تورینگ محاسباتی» جدید، هوش مصنوعی را که وانمود میکند انسان است، با دقت ۸۰ درصد شناسایی میکند.

دفعه بعد که در شبکههای اجتماعی با پاسخی بیش از حد مؤدبانه روبرو شدید، کمی بیشتر دقت کنید. شاید این پاسخ از سوی یک مدل هوش مصنوعی باشد که در تلاش است (و البته ناموفق) تا خود را در میان کاربران عادی پنهان کند.
روز چهارشنبه، پژوهشگرانی از دانشگاه زوریخ، دانشگاه آمستردام، دانشگاه دوک و دانشگاه نیویورک تحقیقی را منتشر کردند که نشان میدهد مدلهای هوش مصنوعی هنوز در مکالمات شبکههای اجتماعی بهراحتی از انسانها قابل تشخیص هستند و لحن عاطفی بیش از حد دوستانهی آنها بزرگترین سرنخ برای شناساییشان است. این تحقیق که ۹ مدل متنباز را در توییتر/ایکس، بلواسکای و ردیت مورد آزمایش قرار داد، دریافت که طبقهبندیکنندههای توسعهدادهشده توسط پژوهشگران، پاسخهای تولیدی هوش مصنوعی را با دقت ۷۰ تا ۸۰ درصد تشخیص میدهند.
این مطالعه چیزی را معرفی میکند که نویسندگان آن را «آزمون تورینگ محاسباتی» مینامند تا ارزیابی کنند مدلهای هوش مصنوعی تا چه حد به زبان انسان نزدیک میشوند. این چارچوب بهجای تکیه بر قضاوت ذهنی انسان در مورد طبیعی بودن متن، از طبقهبندیکنندههای خودکار و تحلیلهای زبانشناختی برای شناسایی ویژگیهای متمایزکننده محتوای ماشینی از محتوای انسانی استفاده میکند.
پژوهشگران نوشتند: «حتی پس از بهینهسازی، خروجیهای مدلهای زبان بزرگ همچنان به وضوح از متن انسانی قابل تشخیص هستند، بهویژه در لحن و بیان عواطف.» این تیم به سرپرستی نیکولو پاگان در دانشگاه زوریخ، استراتژیهای بهینهسازی مختلفی، از دستورنویسی ساده گرفته تا تنظیم دقیق (fine-tuning) را آزمودند، اما دریافتند که نشانههای عاطفی عمیقتر همچنان سرنخهای قابل اعتمادی برای تشخیص این موضوع هستند که یک تعامل متنی آنلاین توسط یک چتبات هوش مصنوعی نوشته شده و نه یک انسان.
سرنخ خشونت کلامی
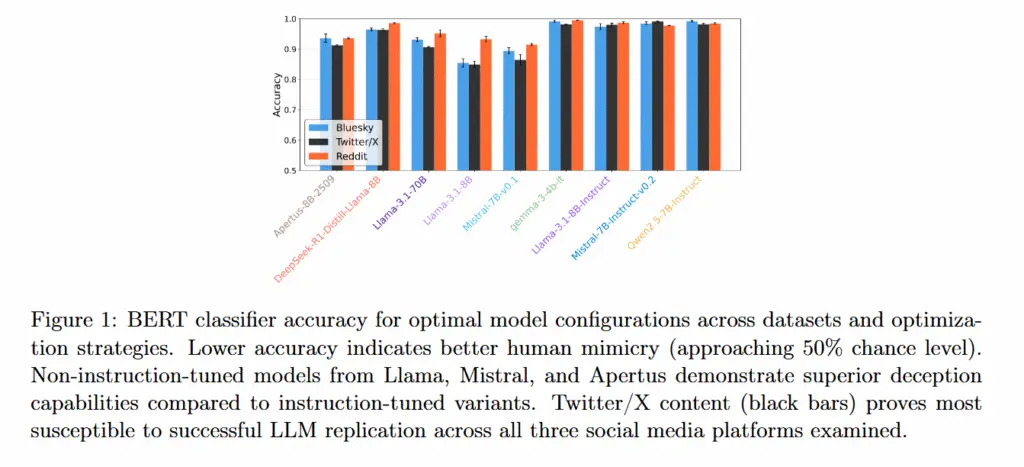
در این مطالعه، پژوهشگران ۹ مدل زبان بزرگ را مورد آزمایش قرار دادند: Llama 3.1 8B, Llama 3.1 8B Instruct, Llama 3.1 70B, Mistral 7B v0.1, Mistral 7B Instruct v0.2, Qwen 2.5 7B Instruct, Gemma 3 4B Instruct, DeepSeek-R1-Distill-Llama-8B و Apertus-8B-2509.
هنگامی که از مدلهای هوش مصنوعی خواسته شد به پستهای واقعی کاربران در شبکههای اجتماعی پاسخ دهند، این مدلها در تقلید از سطح منفینگری معمولی و بیان عواطف خودانگیخته که در پستهای انسانی رایج است، با مشکل مواجه شدند. در هر سه پلتفرم، امتیاز خشونت کلامی (toxicity) آنها بهطور مداوم پایینتر از پاسخهای واقعی انسانها بود.
برای مقابله با این ضعف، پژوهشگران استراتژیهای بهینهسازی (از جمله ارائه نمونههای نوشتاری و بازیابی زمینه) را به کار گرفتند که تفاوتهای ساختاری مانند طول جمله یا تعداد کلمات را کاهش داد، اما تفاوت در لحن عاطفی همچنان پابرجا بود. پژوهشگران نتیجه گرفتند: «آزمایشهای جامع بهینهسازی ما این فرضیه را به چالش میکشد که بهینهسازی پیچیدهتر لزوماً به خروجی انسانمانندتری منجر میشود.»
این مطالعه همچنین به یک یافته غیرمنتظره دست یافت: مدلهای تنظیمشده با دستورالعمل (instruction-tuned)، که برای پیروی از دستورات کاربر و رفتار مفید آموزشهای بیشتری دیدهاند، در واقع در تقلید از انسانها عملکرد بدتری نسبت به نسخههای پایه خود دارند. مدلهایی مانند Llama 3.1 8B و Mistral 7B v0.1 بدون تنظیم با دستورالعمل، به تقلید بهتری از انسان دست یافتند و دقت طبقهبندی آنها بین ۷۵ تا ۸۵ درصد بود.
شگفتانگیزتر اینکه، افزایش اندازه مدل نیز هیچ مزیتی نداشت. مدل Llama 3.1 با ۷۰ میلیارد پارامتر، عملکردی برابر یا حتی ضعیفتر از مدلهای کوچکتر ۸ میلیارد پارامتری داشت. این موضوع، فرضیههایی را که معتقد بودند مدلهای بزرگتر ارتباطات طبیعیتری تولید میکنند، به چالش میکشد.
پژوهشگران به یک تضاد اساسی پی بردند: زمانی که مدلهای هوش مصنوعی برای جلوگیری از شناسایی شدن، با سبک نوشتاری انسانها هماهنگ میشدند، از آنچه انسانها واقعاً در پاسخ به همان پستها میگفتند، دورتر میشدند (امتیاز تشابه معنایی آنها با پاسخهای واقعی انسان در پلتفرمهای مختلف از میانگین ۰.۱۸-۰.۳۴ به ۰.۱۶-۰.۲۸ کاهش یافت). برعکس، زمانی که برای تطابق با محتوای پاسخهای انسانی بهینه میشدند، تشخیص مصنوعی بودن متن هوش مصنوعی آسانتر میشد.
در این تحقیق، تکنیکهای بهینهسازی ساده برای کاهش قابلیت شناسایی، عملکرد بهتری نسبت به روشهای پیچیده داشتند. ارائه نمونههای واقعی از پستهای قبلی یک کاربر یا بازیابی زمینه مرتبط، بهطور مداوم تشخیص متن هوش مصنوعی از نوشته انسانی را دشوارتر میکرد، در حالی که رویکردهای پیچیده مانند ارائه توصیفی از شخصیت کاربر به هوش مصنوعی و تنظیم دقیق مدل، تأثیر ناچیز یا معکوسی بر واقعگرایی داشت.

تفاوتهای پلتفرمها نیز در میزان موفقیت هوش مصنوعی در تقلید از کاربران آشکار شد. طبقهبندیکنندههای پژوهشگران، پاسخهای تولیدشده توسط هوش مصنوعی در توییتر/ایکس را با کمترین نرخ دقت (به معنای تقلید بهتر) شناسایی کردند و پس از آن بلواسکای قرار داشت، در حالی که تشخیص متن مصنوعی از انسانی در ردیت از همه آسانتر بود. پژوهشگران معتقدند این الگو هم بازتابدهنده سبکهای مکالمه متمایز هر پلتفرم است و هم نشان میدهد که دادههای هر پلتفرم تا چه حد در آموزش اولیه مدلها نقش داشتهاند.
این یافتهها که هنوز تحت داوری همتا قرار نگرفتهاند، ممکن است پیامدهایی برای توسعه هوش مصنوعی و اصالت محتوا در شبکههای اجتماعی داشته باشد. این مطالعه نشان میدهد که با وجود استراتژیهای مختلف بهینهسازی، مدلهای فعلی با محدودیتهای پایداری در به تصویر کشیدن بیان عواطف خودانگیخته روبرو هستند و نرخ تشخیص آنها همچنان بسیار بالاتر از سطح شانس است. نویسندگان نتیجه میگیرند که شباهت سبکی به انسان و دقت معنایی در معماریهای فعلی «اهدافی متضاد و نه همسو» هستند، که نشان میدهد متن تولیدشده توسط هوش مصنوعی با وجود تلاشها برای انسانیسازی آن، همچنان به وضوح مصنوعی باقی میماند.
در حالی که پژوهشگران همچنان تلاش میکنند تا صدای مدلهای هوش مصنوعی را انسانمانندتر کنند، انسانهای واقعی در شبکههای اجتماعی مدام ثابت میکنند که اصالت اغلب به معنای آشفته، متناقض و گاهی ناخوشایند بودن است. این بدان معنا نیست که یک مدل هوش مصنوعی بهطور بالقوه نمیتواند چنین خروجیای را شبیهسازی کند، بلکه تنها نشان میدهد که این کار بسیار دشوارتر از آن چیزی است که پژوهشگران انتظار داشتند.