
- چارچوبهای امن‑بهصورتپیشفرض متا توابع احتمالی ناامن سیستمعامل و شخص ثالث را میپوشانند تا امنیت را بهصورت پیشفرض قرار دهند، در حالیکه سرعت و سادگی توسعهدهندگان حفظ میشود.
- این چارچوبها به گونهای طراحی شدهاند که با APIهای موجود بهدقت همسان باشند، بر رابطهای عمومی و پایدار تکیه کنند و پذیرش توسط توسعهدهندگان را با کاهش اصطکاک و پیچیدگی به حداکثر برسانند.
- هوش مصنوعی تولیدی و خودکارسازی، پذیرش چارچوبهای امن را در مقیاس بزرگ تسریع میکنند و امکان اعمال مداوم امنیت و مهاجرت کارآمد در کل کدبیس وسیع متا را فراهم میسازند.
گاهی توابع موجود در سیستمعاملها یا ارائهشده توسط شخص ثالث، خطر سوءاستفادهای دارند که میتواند امنیت را به خطر بیندازد. برای رفع این ریسک، این توابع را با چارچوبهای امن‑بهصورتپیشفرض خود میپوشانیم یا جایگزین میکنیم. این چارچوبها نقش مهمی در کمک به مهندسان امنیت و نرمافزار ما برای نگهداری و ارتقای امنیت کدبیسها دارند، در حالی که سرعت توسعهدهندگان حفظ میشود.
اما پیادهسازی این چارچوبها با چالشهای عملی همراه است، از جمله توازنهای طراحی. به عنوان مثال، ساخت یک چارچوب امن بر پایهٔ APIهای اندروید نیازمند تعادل دقیقی بین امنیت، قابلیت استفاده و نگهداری است.
با ظهور ابزارهای مبتنی بر هوش مصنوعی و خودکارسازی، میتوانیم پذیرش این چارچوبها را در کل کدبیس بزرگ متا مقیاسبندی کنیم. هوش مصنوعی میتواند در شناسایی الگوهای ناامن، پیشنهاد یا اعمال خودکار جایگزینی چارچوبهای امن و نظارت مستمر بر انطباق کمک کند. این نه تنها سرعت مهاجرت را افزایش میدهد، بلکه اطمینان از اعمال مستمر امنیت در مقیاس وسیع را نیز فراهم میکند.
بههمین ترتیب، این استراتژیها تیمهای توسعه ما را قادر میسازند تا نرمافزارهای با امنیت بالا را بهصورت کارآمد عرضه کنند، دادهها و اعتماد کاربران را محافظت کنند و در عین حال بهرهوری بالای توسعهدهندگان را در کل اکوسیستم گستردهٔ متا حفظ کنند.
چگونگی طراحی چارچوبهای امن‑بهصورتپیشفرض در متا
طراحی چارچوبهای امن‑بهصورتپیشفرض برای استفاده توسط تعداد زیادی از توسعهدهندگانی که ویژگیهای متفاوتی را در برنامههای متعددی منتشر میکنند، یک چالش جالب است. دغدغههای متعدلی مانند قابلیت کشف، قابلیت استفاده، نگهداری، عملکرد و مزایای امنیتی با یکدیگر رقابت میکنند.
از نگاه عملی، توسعهدهندگان تنها زمان محدودی برای نوشتن کد در هر روز دارند. هدف چارچوبهای ما ارتقای امنیت محصول است، در حالی که در اکثر موارد بهصورت نامرئی و بدون اصطکاک عمل میکنند تا از کاهش سرعت کار توسعهدهندگان جلوگیری کنند. این به این معنی است که باید تمام دغدغههای مطرحشده را بهدرستی متعادل کنیم. اگر تعادل نادرست برقرار شود، برخی توسعهدهندگان ممکن است از استفاده از چارچوبهای ما خودداری کنند که میتواند توانایی ما در جلوگیری از آسیبپذیریهای امنیتی را کاهش دهد.
بهعنوان مثال، اگر چارچوبی را طراح کنیم که امنیت محصول را در یک حوزه بهبود میبخشد اما سه مفهوم جدید معرفی میکند و از توسعهدهندگان میخواهد در هر نقطهکد پنج اطلاعات اضافه ارائه دهند، برخی توسعهدهندگان برنامه ممکن است راهی برای دور زدن این چارچوب پیدا کنند. از سوی دیگر، اگر همان چارچوبها را ارائه دهیم که استفاده از آنها بهسادگی ممکن است، اما مصرف قابلتوجهی از پردازشگر (CPU) و حافظه (RAM) داشته باشند، برخی توسعهدهندگان نیز ممکن است به دلایل متفاوت، برای دور زدن استفاده از آنها تلاش کنند.
این مثالها ممکن است کمی واضح به نظر برسد، اما بر پایهٔ تجارب واقعی در طول بیش از ۱۰ سال گذشته در توسعه حدود ۱۵ چارچوب امن‑بهصورتپیشفرض برای اندروید و iOS استوار هستند. در طول این زمان، بهترین روشها برای طراحی و پیادهسازی این چارچوبهای جدید را برقرار کردهایم.
در حد امکان، یک چارچوب مؤثر باید اصول زیر را تجسم دهد:
- API چارچوب امن باید شبیه به API موجود باشد. این کار بار ذهنی کاربران چارچوب را کاهش میدهد، توسعهدهندگان چارچوب امنیتی را مجبور میکند تا پیچیدگی تغییرات را به حداقل برسانند و تبدیل خودکار کد از استفادهٔ API ناامن به API امن را آسانتر میکند.
- چارچوب باید خود بر پایهٔ APIهای عمومی و پایدار ساخته شود. APIهای ارائهکنندگان سیستمعامل و شخص ثالث بهطور مداوم، بهویژه نسخههای غیر عمومی، تغییر میکنند. حتی اگر دسترسی به این APIها از نظر فنی در برخی موارد مجاز باشد، ساختن بر پایهٔ APIهای خصوصی منجر به مواجههٔ مداوم با مشکلات اضطراری (در بهترین حالت) و سرمایهگذاری بینتیجه در چارچوبهایی میشود که بهسادگی با نسخههای جدیدتر سیستمعاملها و کتابخانهها کار نمیکنند (در بدترین حالت).
- چارچوب باید حداکثر تعداد کاربران برنامه را پوشش دهد، نه فقط موارد امنیتی. نباید یک چارچوب امنیتی وجود داشته باشد که تمام مشکلات امنیتی را پوشش دهد، و هر مشکل امنیتی بهطور کلی گسترده نیست که شایستگی یک چارچوب اختصاصی را داشته باشد. با این حال، هر چارچوب امنیتی باید برای تمام برنامهها و نسخههای سیستمعامل یک پلتفرم خاص قابل استفاده باشد. کتابخانههای کوچک سریعتر ساخته و مستقر میشوند و نگهداری و توضیح آنها برای توسعهدهندگان برنامه آسانتر است.
حالا که به فلسفهٔ طراحی چارچوبهای خود نگاهی انداختهایم، نگاهی به یکی از پرکاربردترین چارچوبهای امنیتی اندروید، SecureLinkLauncher خواهیم داشت.
SecureLinkLauncher: جلوگیری از ربودن Intent در اندروید
SecureLinkLauncher (SLL) یکی از چارچوبهای امن پرکاربرد ماست. SLL برای جلوگیری از نشت دادههای حساس از طریق سیستم Intentهای اندروید طراحی شده است. این چارچوب رویکرد ما به چارچوبهای امن‑بهصورتپیشفرض را نشان میدهد؛ بهطوری که متدهای بومی راهاندازی Intentهای اندروید را با اعتبارسنجی حوزه و بررسیهای امنیتی میپوشاند و از آسیبپذیریهای رایج مانند ربودن Intent جلوگیری میکند، بدون آنکه سرعت یا آشنایی توسعهدهندگان به خطر بیفتد.
سیستم شامل ارسالکنندهها و دریافتکنندههای Intent است. SLL برای ارسالکنندههای Intent هدفگذاری شده است.
SLL یک API معنایی ارائه میدهد که بهدقت API آشنای Android Context را برای راهاندازی Intentها بازتاب میکند، از جمله متدهایی مانند startActivity() و startActivityForResult(). بهجای فراخوانی مستقیم API اندروید که ممکن است ناامن باشد، مثل context.startActivity(intent);، توسعهدهندگان از SecureLinkLauncher با الگوی فراخوانی مشابه استفاده میکنند؛ برای مثال، SecureLinkLauncher.launchInternalActivity(intent, context);. بهصورت داخلی، SecureLinkLauncher به API پایدار Android startActivity() واگذار میشود، بهطوری که تمام اجرای Intentها بهصورت امن تأیید و توسط چارچوب محافظت میشوند.
public void launchInternalActivity(Intent intent, Context context) {
// Verify that the target activity is internal (same package)
if (!isInternalActivity(intent, context)) {
throw new SecurityException("Target activity is not internal");
}
// Delegate to Android's startActivity to launch the intent
context.startActivity(intent);
}
بهطور مشابه، بهجای فراخوانی مستقیم context.startActivityForResult(intent, code);، توسعهدهندگان از SecureLinkLauncher.launchInternalActivityForResult(intent, code, context) استفاده میکنند. SecureLinkLauncher (SLL) متدهای startActivity() اندروید و متدهای مرتبط را میپوشاند و قبل از واگذاری به API بومی اندروید، اعتبارسنجی حوزه را اعمال میکند. این رویکرد امنیت را بهصورت پیشفرض فراهم میکند و در عین حال معنا و مفهوم آشنا برای راهاندازی Intentهای اندروید را حفظ میکند.
یکی از رایجترین روشهایی که دادهها از طریق Intentها نشت میکنند، بهدلیل هدفگذاری ناصحیح Intent است. بهعنوان مثال، Intent زیر بهصورت خاص به یک بسته هدفگذاری نشده است. این به این معناست که هر برنامهای که فیلتر <intent‑filter> مطابقت داشته باشد میتواند این Intent را دریافت کند. در حالی که هدف توسعهدهنده ممکن است ارسال Intent به برنامهٔ Facebook بر پایهٔ URL باشد، در واقعیت هر برنامهای، حتی برنامهٔ مخرب، میتواند یک <intent‑filter> اضافه کند که آن URL را مدیریت کند و Intent را دریافت نماید.
Intent intent = new Intent(FBLinks.PREFIX + "profile");
intent.setExtra(SECRET_INFO, user_id);
startActivity(intent);
// startActivity can’t ensure who the receiver of the intent would be
در مثال زیر، SLL اطمینان میدهد که Intent به یکی از برنامههای خانواده هدایت شود، همانطور که دامنهٔ صریح برای Intentهای ضمنی توسط توسعهدهنده مشخص شده است. بدون SLL، این Intentها میتوانند به برنامههای خانواده و غیرخانواده هر دو مسیر یابند و ممکن است SECRET_INFO را در معرض برنامههای شخص ثالث یا مخرب روی دستگاه کاربر قرار دهند. با اعمال این دامنه، SLL میتواند چنین نشت اطلاعاتی را جلوگیری کند.
SecureLinkLauncher.launchFamilyActivity(intent, context);
// launchFamilyActivity would make sure intent goes to the meta family apps
در یک محیط معمولی اندروید، دو دامنه – داخلی و خارجی – ممکن است برای مدیریت Intentها درون یک برنامه و بین برنامههای مختلف کافی بهنظر برسد. با این حال، اکوسیستم متا منحصر بهفرد است و شامل چندین برنامه مانند Facebook، Instagram، Messenger، WhatsApp و انواع مختلف آن (مثلاً WhatsApp Business) میشود. پیچیدگی ارتباط بین فرآیندها میان این برنامهها کنترل دقیقتری بر دامنهٔ Intentها میطلبد. برای رفع این نیاز، SLL رویکردی دقیقتر برای تعیین دامنهٔ Intent ارائه میدهد که دامنههای متناسب با موارد کاربرد خاص را فراهم میکند:
- دامنهٔ خانواده: ارتباط امن بین برنامههای متعلق به متا را فراهم میکند و اطمینان میدهد که Intentها فقط از یک برنامهٔ متا به برنامهٔ دیگر متا ارسال شوند.
- دامنهٔ کلید مشابه: ارسال Intent را به برنامههای متایی که با کلید یکسان امضا شدهاند محدود میکند (همهٔ برنامههای متا با یک کلید امضا نشدهاند) و لایهٔ افزودهای از امنیت و اعتماد ارائه میدهد.
- دامنهٔ داخلی: ارسال Intent را فقط درون همان برنامه محدود میکند.
- دامنهٔ شخص ثالث: اجازه میدهد Intentها به برنامههای شخص ثالث ارسال شوند، در حالی که مانع از پردازش آنها توسط برنامههای خود متا میشود.
با بهرهگیری از این دامنهها، توسعهدهندگان میتوانند اطمینان حاصل کنند که دادههای حساس بهصورت امن و عمدی درون اکوسیستم متا بهاشتراک گذاشته میشوند، در عین حال از دسترسیهای ناخواسته یا مخرب محافظت میشود. قابلیتهای دقیق تعیین دامنهٔ Intentهای SLL که بر پایهٔ اصول چارچوبهای امن‑بهصورتپیشفرض مطرح شده است، توسعهدهندگان را قادر میسازد برنامههای مقاومتر و امنتری بسازند که نیازهای منحصر بهفرد اکوسیستم پیچیدهٔ متا را برآورده میکنند.
به کارگیری هوش مصنوعی تولیدی برای استقرار چارچوبهای امن‑بهصورتپیشفرض در مقیاس بزرگ
استفاده از این چارچوبها در یک کدبیس بزرگ کار سادهای نیست. پیچیدگی اصلی انتخاب دامنهٔ صحیح است؛ چراکه این انتخاب به اطلاعاتی وابسته است که بهسرعت در نقاط فراخوانی موجود در دسترس نیست. اگرچه میتوان تصور کرد که تحلیلی قطعی سعی در استنتاج دامنه بر پایهٔ جریانهای داده داشته باشد، این کار کار بزرگی خواهد بود. علاوه بر این، احتمالاً بهدنبال تعادل بین دقت و مقیاسپذیری خواهد بود.
بهجای آن، ما استفاده از هوش مصنوعی تولیدی را در این زمینه بررسی کردیم. هوش مصنوعی میتواند کد اطراف را بخواند و سعی کند دامنه را بر پایهٔ ناممتغیرها و توضیحات اطراف نقطهٔ فراخوانی استنتاج کند. اگرچه این روش همیشه بینقص نیست، نیازی به کامل بودن ندارد؛ فقط کافیست پیشبینیهای کافی و قابل قبولی ارائه دهد تا مالکان کد بتوانند با یک کلیک، پچهای پیشنهادی را بپذیرند.
اگر پچها در اکثر موارد درست باشند، این ابزار صرفهجوئی بزرگی در زمان است که استقرار مؤثر چارچوب را ممکن میسازد. این کار تکمیلکنندهٔ پژوهش اخیر ما بر روی AutoPatchBench است؛ بنچمارکی که برای ارزیابی ژنراتورهای پچ مبتنی بر هوش مصنوعی که از مدلهای بزرگ زبانی (LLM) استفاده کنند تا بهصورت خودکار پچهای امنیتی را پیشنهاد و اعمال کنند، طراحی شده است. چارچوبهای امن‑بهصورتپیشفرض نمونهای عالی از نوع تغییرات کد هستند که یک سیستم خودکار پچگذاری میتواند برای ارتقاء امنیت کدبیس اعمال کند.
ما چارچوبی ساختهایم که از Llama بهعنوان فناوری اصلی استفاده میکند؛ این چارچوب مکانهای موجود در کدبیس که میخواهیم مهاجرت کنیم را میگیرد و پچهایی برای پذیرش توسط مالکان کد پیشنهاد میدهد:
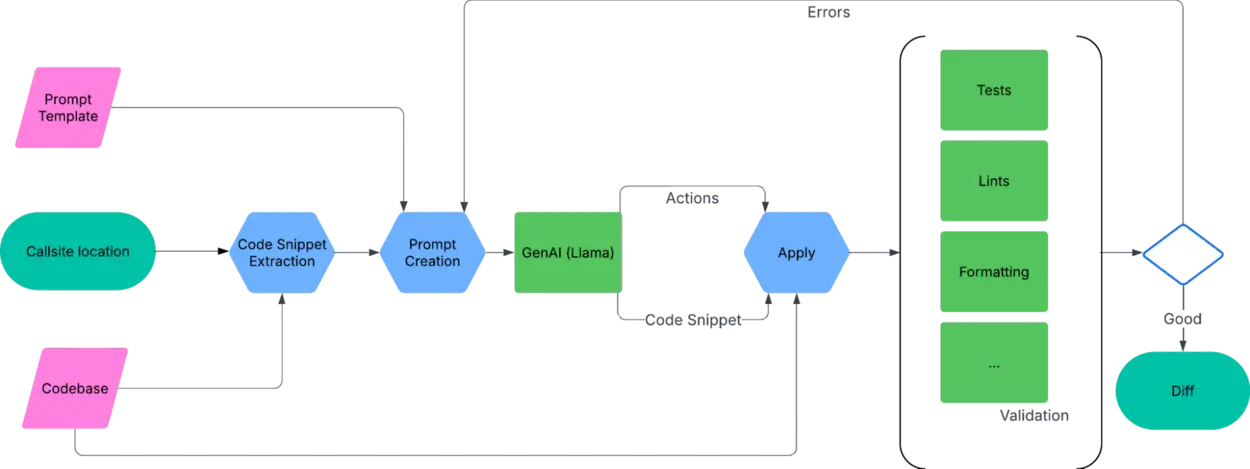
ساخت Prompt
گردش کار هوش مصنوعی با نقطهٔ فراخوانیای که میخواهیم مهاجرت کنیم، بههمراه مسیر فایل و شمارهٔ خط مربوطه آغاز میشود. این مکان برای استخراج یک بخش کد از کدبیس استفاده میشود؛ به این معنی که فایل حاوی نقطهٔ فراخوانی باز شده، ۱۰ تا ۲۰ خط قبل و بعد از مکان فراخوانی کپی میشود و در قالب Prompt قرار میگیرد که راهنمای کلی برای انجام مهاجرت ارائه میدهد. این توصیف شباهت زیادی به راهنمای ورود به چارچوب برای مهندسان انسانی دارد.
هوش مصنوعی تولیدی
سپس Prompt به مدل Llama (llama4‑maverick‑17b‑128e‑instruct) ارائه میشود. از مدل درخواست میشود دو خروجی تولید کند: بخش کد اصلاحشده که نقطهٔ فراخوانی در آن مهاجرت یافته است؛ و بهطور اختیاری، برخی اقدامات (مانند افزودن یک import در بالای فایل). هدف اصلی این اقدامات، دور زدن محدودیتهای این روش است که تمام تغییرات کد بهصورت محلی و محدود به بخش کد نمیباشند. اقدامات به مدل اجازه میدهد تا برای برخی تغییرات محدود و قطعی، بهخارج از بخش کد دسترسی پیدا کند. این برای افزودن importها یا وابستگیها مفید است که بهندرت بهصورت محلی در بخش کد وجود دارند، اما برای کامپایل کد ضروریاند. سپس بخش کد اصلاحشده بهدوباره در کدبیس قرار میگیرد و اقدامات اعمال میشوند.
اعتبارسنجی
در نهایت، مجموعهای از اعتبارسنجیها را روی کدبیس انجام میدهیم. این اعتبارسنجیها را هم با تغییرات هوش مصنوعی و هم بدون آن اجرا میکنیم و فقط اختلافات را گزارش می نماییم:
- بررسیهای Lint: Linters را دوباره اجرا میکنیم تا اطمینان حاصل شود که مشکل Lint رفع شده و خطاهای جدیدی توسط تغییرات وارد نشدهاند.
- کامپایل: فایل هدف را کامپایل و تستهای مربوطه را اجرا میکنیم. این هدف برای کشف تمام باگها نیست (برای این منظور به CI متکی هستیم)، اما بازخورد اولیهای به هوش مصنوعی دربارهٔ تغییرات (مانند خطاهای کامپایل) میدهد.
- قالببندی: کد برای جلوگیری از مشکلات قالببندی فرمت میشود. خطاهای قالببندی به هوش مصنوعی بازخورد داده نمیشود.
اگر در طول اعتبارسنجی خطاهایی رخ داد، پیامهای خطا به همراه بخش کد «اصلاحشده» در Prompt قرار میگیرند و از هوش مصنوعی خواسته میشود دوباره سعی کند. این حلقه را پنج بار تکرار میکنیم و در صورت عدم ایجاد اصلاح موفق، از ادامه کار صرف نظر میکنیم. اگر اعتبارسنجی موفق باشد، پچی برای بازبینی انسانی ارسال میکنیم.
طراحی متفکرانه چارچوبها با اتوماسیون هوشمند
با پایبندی به اصول طراحی اصلی مانند ارائهٔ APIای که بهدقت با الگوهای موجود در سیستمعاملها همخوانی داشته باشد، تکیه بر APIهای عمومی و پایدار سیستمعامل، و طراحی چارچوبهایی که کاربران گستردهای را پوشش میدهند نه موارد کاربرد خاص، توسعهدهندگان میتوانند ویژگیهای مستحکم و امن‑بهصورتپیشفرض بسازند که بهسلاسة در کدبیسهای موجود ادغام شوند.
این اصول طراحی همانند ما را قادر میسازند تا از هوش مصنوعی برای اتخاذ روان چارچوبها در مقیاس بزرگ بهرهبرداری کنیم. اگرچه همچنان چالشهایی در مورد دقت کدهای تولیدشده وجود دارد – به عنوان مثال، انتخاب دامنهٔ نادرست توسط هوش مصنوعی، استفاده از سینتکس نادرست، و غیره – اما طرح حلقه بازخورد داخلی به مدل LLM این امکان را میدهد که بهصورت خودکار از مشکلات قابلحل عبور کند بدون نیاز به دخالت انسانی، که مقیاسپذیری را افزایش داده و خستگی توسعهدهندگان را کاهش میدهد.
در داخل شرکت، این پروژه نشان داد که هوش مصنوعی میتواند برای پذیرش چارچوبهای امنیتی در کدبیس متنوع ما بهطور مؤثری عمل کند، بهگونهای که کمترین اختلال را برای توسعهدهندگان ما ایجاد میکند. هماکنون پروژههای متعددی بهکار گرفتهاند که مشکلات مشابه را در کدبیسها و زبانهای مختلف – از جمله C/++ – با استفاده از مدلها و تکنیکهای اعتبارسنجی گوناگون حل میکنند. انتظار داریم این روند تا سال ۲۰۲۶ ادامه یابد و تسریع شود، زیرا توسعهدهندگان با ابزارهای پیشرفتهٔ هوش مصنوعی و کیفیت کدهای تولیدی آنها آشناتر میشوند.
با رشد کدبیس ما و پیچیدهتر شدن تهدیدات امنیتی، ترکیب طراحی متفکرانه چارچوبها و اتوماسیون هوشمند برای حفاظت از دادههای کاربران و حفظ اعتماد در مقیاس وسیع ضروری خواهد بود.